a statisztikai értékek feldolgozása

2022-01-08 Excel 2019
A pivot táblában négy számított objektumot hozhatunk létre. Ebből kettőnek a képletét közvetlenül a felhasználó szerkeszti meg, a másik kettőét a program állítja össze. Az első csoportba tartozik a számított mező és a számított tétel, a másodikba a statisztikai mező és a statisztikai mező értékeinek feldolgozása. Ebben a cikkben a második csoportba tartozó objektumokat mutatom be.
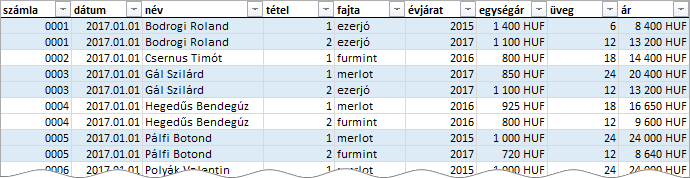
A példáinkban szereplő pivot táblák forrása egy borászat 2017. első negyedéves értékesítéseit tartalmazó, „eladások” nevű adatbázis-táblázat. Mezői a következők. Számla: a számla sorszáma. Dátum: a vásárlás napja. Név: a vásárló neve. Tétel: a tétel sorszáma a számlán belül. Fajta: a vásárolt bor szőlő-fajtája. Évjárat: a termés éve. Egységár: egy üveg bor ára. Üveg: vásárolt palackok száma. Ár: a tétel ára.
A statisztikai mező egy képleten alapuló számított objektum a pivot táblában. A program a felhasználó által kiválasztott művelet függvényével vizsgálja a pivot tábla Értékek területén álló mező csoportjait, amelyeket a sor- és oszlop mezők tételei határoznak meg. Képletének általános alakja: STATISZTIKAI FÜGGVÉNY(adat-csoport). Tehát, ahány csoport annyi képlet, és annyi eredmény, vagy másként fogalmazva, annyi statisztikai érték.
Képezzük az eladások összegét pivot táblával, szőlőfajta és, azon belül, évjárat szerint, havi bontásban. A Hónapok mezőt a programmal hozassuk létre, a dátum mező Oszlopok területre helyezésével.
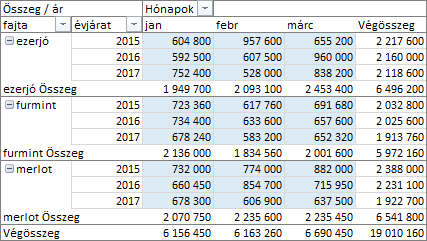
A pivot tábla statisztikai értékeivel további számításokat végezhetünk. A feldolgozáshoz használt képletet, ebben az esetben is, a program állítja össze, nekünk csak a műveletet paramétereit kell beállítanunk. A számítás eredménye a statisztikai érték cellájában, azt felülírva, jelenik meg. Talán ezért nevezi a program a statisztikai értékek feldolgozását „megjelenítésnek”?!
A művelet részleteit beállíthatjuk a pivot tábla segédablakában és magában a pivot táblában is. A segédablak Értékek területen álló mező menüjéből az Értékmező-beállítások… utasítással hívható az a parancstábla, amelynek Az értékek megjelenítése lapján találjuk a számítások vezérlőit. Felül az eljárások-, alatta a mező- és a tétel-lista. Utóbbi kettő csak akkor aktív, ha a kiválasztott számítás paraméter megadását igényli. Az aktív mező-lista a forrás táblázat minden oszlopát tartalmazza, de természetesen a számítás paramétere csak a pivot táblában szereplő mező lehet. Ha véletlenül mellényúlunk, akkor a program a statisztikai értékeket a #HIÁNYZIK hibaértékre cseréli.
A pivot táblában tetszőleges statisztikai érték helyi menüjéből, Az értékek megjelenítése utasítással jeleníthetjük meg a számítások listáját. Ha paraméteres eljárást választottunk, akkor azt, egy automatikusan megjelenített kis parancstáblán kell megadnunk. Ezen a panelon már csak a pivot táblában szereplő mezőket sorolja fel a program.
Még mielőtt elmerülnénk a részletekben, nevezzük meg a statisztikai mező kiszámított értékeit.

[1] A „statisztikai érték” a belső csoportosító mezők tételei által meghatározott adat-csoport statisztikai vizsgálatának eredménye. [2] A „csoport érték” a külső csoportosító mezők tételei által meghatározott adat-csoport statisztikai értéke. [3] A sor mező tételei által meghatározott adat-csoport statisztikai értéke a „sor érték”, az oszlop mező tételei által meghatározott adat-csoport statisztikai értéke a „oszlop érték”. [4] A statisztikai mező összes adatának statisztikai értéke a „tábla érték”.
Kezdjük az ismerkedést a „göngyölített összeg” számítással! A számítás paramétere az évjárat mező legyen!
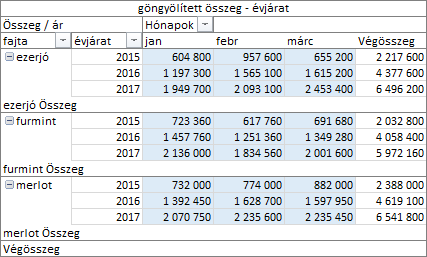
Sok a szám! Nehéz kisilabizálni, hogy milyen művelet történt. Vezessünk be egy egyszerű jelölés-rendszert a pivot táblánk statisztikai értékeinek azonosítására! [statisztikai érték] <fajta-név első betűje><évjárat utolsó számjegye><hónap első betűje>. Például: m7f jelentése merlot, 2017-es, február. [csoport érték] <fajta-név első betűje><hónap első betűje>. Az utolsó oszlopban: <fajta-név első betűje>. [sor érték] <fajta-név első betűje><évjárat utolsó számjegye>. [oszlop érték] <fajta-név első betűje><hónap első betűje>. [tábla érték] nagy Ö betű. Valahogy így!
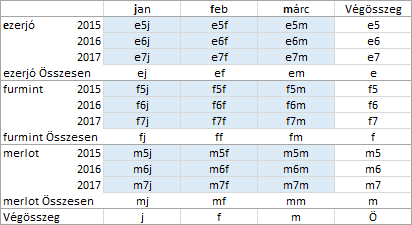
Az azonosítókat használva, most már meg tudjuk jeleníteni a „göngyölített összeg” számítás három változatának képletét. A mező-paraméter legyen újra a évjárat.
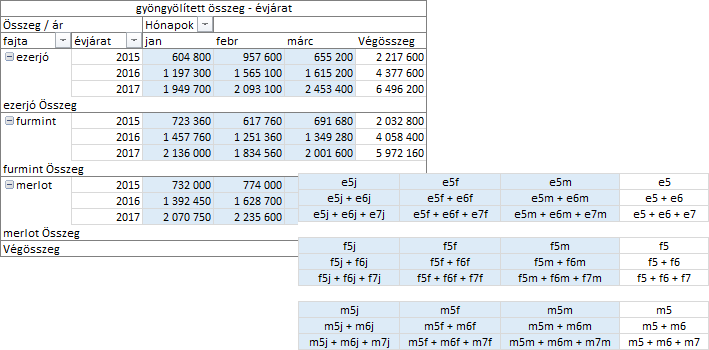
Ahogy látjuk a belső sor mezőt választva a program a statisztikai értékeket és a sor értékeket göngyölíti, függőlegesen, a külső sor mező tételeiben. Most válasszuk a számítás paraméterének a fajta mezőt!
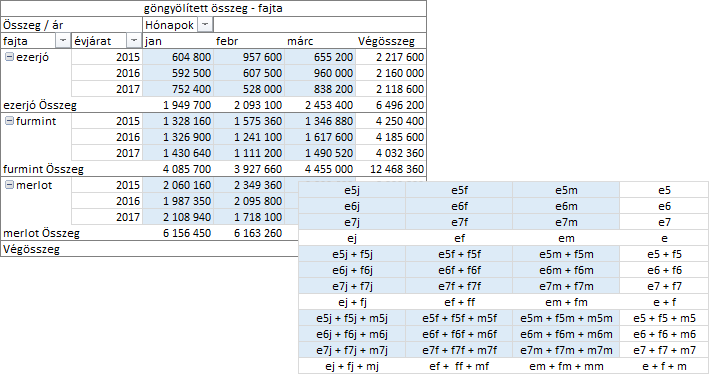
Külső sor mező választása esetén az azonos címkéjű statisztikai értékek, a sor értékek és a csoport értékek kerülnek függőlegesen göngyölítve. Vizsgáljuk meg a harmadik lehetőséget. A számítás paramétere a Hónapok mező legyen!
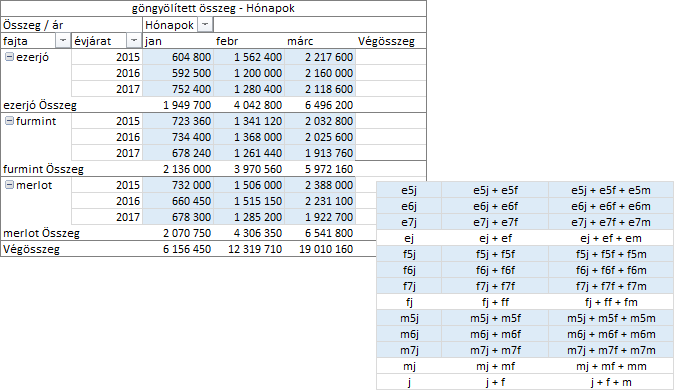
Oszlop mező választása esetén a statisztikai értékek, az oszlop értékek és a csoport értékek kerülnek vízszintesen göngyölítve. Általánosítva a tapasztaltakat, ha sor mezőt választunk a művelethez, akkor a göngyölítés felülről lefelé halad, ha oszlop mezőt, akkor balról jobbra. A program belső csoportosító (sor- vagy oszlop-) mező megadása esetén, a statisztikai értékek göngyölítését a külső csoportosító mező tételeiben újrakezdi, külső csoportosító mező választásakor, az azonos címkéjű tételek statisztikai értékét göngyölíti.
A következő számítás az „eltérés” legyen, amely meghatározott statisztikai értékek különbségét adja. Paraméterként meg kell adnunk a számítás dimenzióját meghatározó mezőt és a számítás viszonyítási alapját adó tételt. A tétel-deklaráció lehet abszolút, a mező egy tetszőleges tételét megnevezve, vagy relatív, a képletet tartalmazó tétel egyik szomszédjának a pozícióját megadva: előző, következő. Számítsuk ki a havi bevételek változását évjárat és fajta szerint, az előző hónaphoz képest!
A statisztikai értékek feldolgozásának eredményét a számítások lista Normál tételével törölhetjük. Az utasítás hatására a pivot táblában megjelennek a statisztikai értékek. Ha csak a feldolgozás képletét módosítjuk, akkor a program automatikusan törli az előző számítás eredményét. Tehát nekünk, a módosítás előtt, nem kell visszaállítanunk az eredeti állapotot.
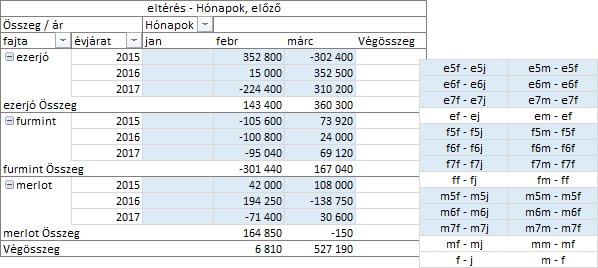
Ismételjük meg számítást, de most a viszonyítási alap a januári bevételünk legyen! Nem kockáztatunk túl sokat, ha kijelentjük, a változás februári értékei nem fognak változni.
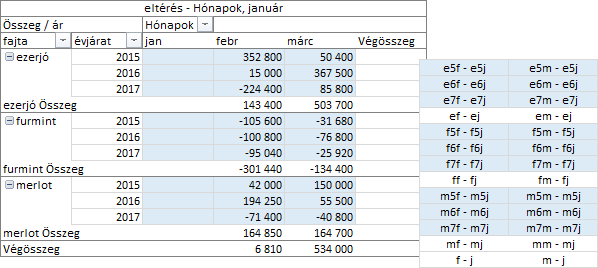
Az „eltérés” nevű számítással a statisztikai értékek és a viszonyítási alap különbségeit képeztük. A változást százalékosan is megadhatjuk a „százalékos eltérés” számítással. A viszonyítási alap megadási módja azonos az előbb ismertetettel. A paraméterek legyenek a Hónapok mező és az előző hónap statisztikai értéke.
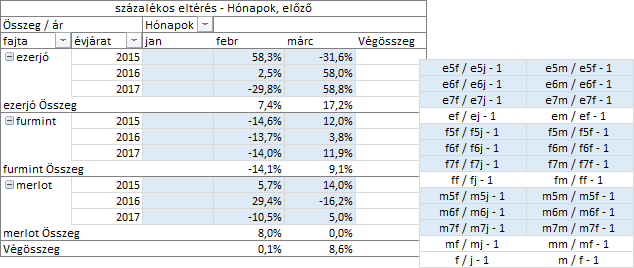
A százalékos megjelenítés mechanizmusát nem ismerem, ezért a képletekből hiányoznak a konvertáló műveletek, de a számítás lényegét ez nem befolyásolja. A szokásos két tizedest, a jó olvashatóság érdekében, számformátummal, egyre csökkentettem.
A további százalékos számítások tárgyalását folytassuk a „göngyölített összeg százalékban” nevű eljárással. A mező-paraméter legyen most is a Hónapok mező!
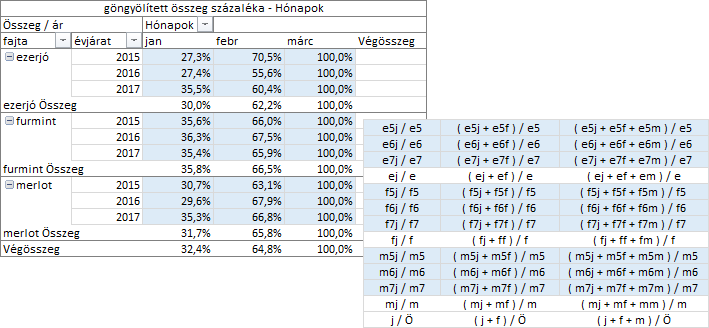
A göngyölített összegek osztója az azonos sorban álló összes statisztikai érték összege, amely a sor értékkel azonos. A képletek áttekinthetőségének érdekében az osztóban nem a sor összes statisztikai értékének összegét képeztem, hanem csak a sor értéket szerepeltettem.
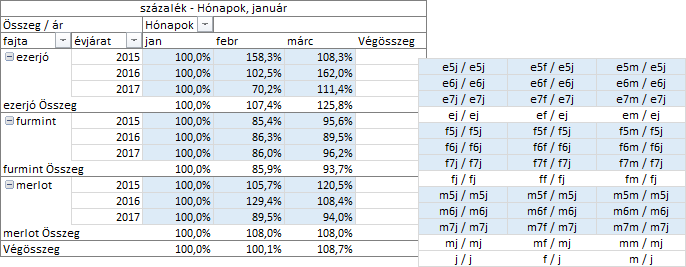
A „százalék” nevű számítás a mező-paraméterében megadott mező tételeinek statisztikai értékeit a mező egy másik, relatív vagy abszolút módon meghatározott, tételének statisztikai értékéhez hasonlítja és az eredményt százalékos formában jeleníti meg. Válasszuk most is a Hónapok mezőt és annak január tételét!
A „sorösszeg százaléka” és az „oszlopösszeg százaléka” számítások testvérek: a statisztikai értékek nagyságát adják eredményül a sor érték illetve az oszlop érték százalékában. Mi az utóbbit próbáljuk ki, mert ez az összetettebb dimenziója a pivot táblánknak!
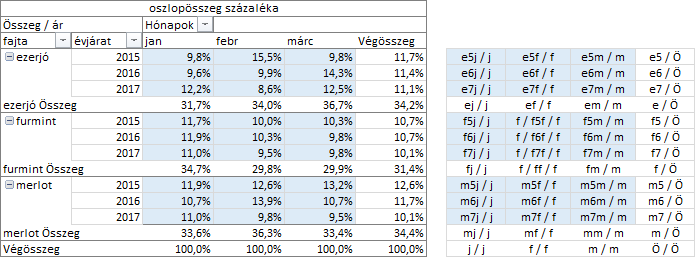
A „végösszeg százaléka” számítás a statisztikai értékek nagyságát adja eredményül a tábla érték százalékában.
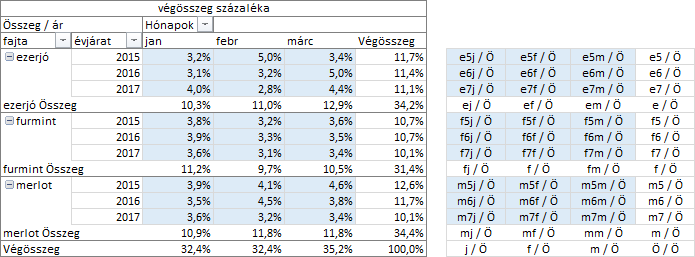
A külső csoportosító mező tételeinek százalékos összetételét a „szülőösszeg százaléka” nevű számítással képezhetjük. Paraméterként a külső csoportosító mezőt kell megadnunk.
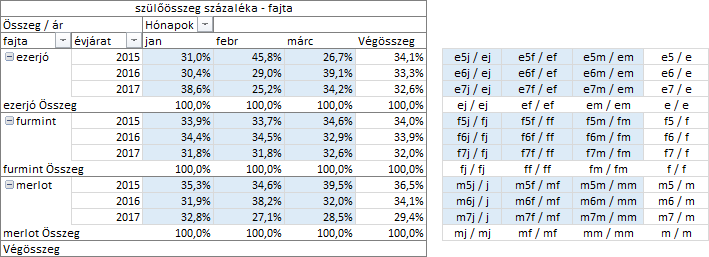
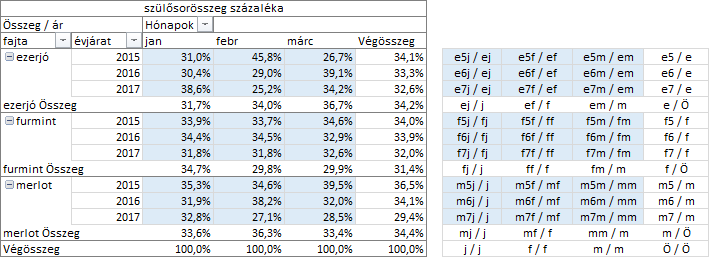
Ennek a számításnak a kiegészítése a „szülősorösszeg százaléka” és a „szülőoszlop összeg százaléka” nevű eljárások, amellyel nemcsak a külső csoportosító mező-, hanem a sor- illetve az oszlop értékek százalékos összetételét is kiszámíthatjuk. Ha az oszlop értékek összetételét vizsgáljuk, akkor a „szülősorösszeg százaléka” számítást, ha a sor értékekét, akkor a „szülőoszlopösszeg százaléka” eljárást kell alkalmaznunk. Képezzük a fajta mező statisztikai értékeinek-, és az oszlop értékek százalékos összetételét!
A számítások listájában találunk két rangsoroló számítást is: „A legkisebbtől a legnagyobbig rangsorolva…”, „A legnagyobbtól a legkisebbig rangsorolva…”. A számítások a statisztikai értékek rangsor-pozícióját adják a paraméterként megadott mező tételeinek rangsorában.
A számítás paramétere a mező, amelynek tételeit rangsorolni szeretnénk. [1] Ha az évjárat mezőt adjuk meg, akkor az egyes szőlőfajták tételeinek rangsorát kapjuk, havi bontásban. [2] Ha a Hónapok mező a számítás paramétere, akkor a hónapok rangsorát kapjuk, szőlőfajták és azon belül, évjáratok szerint. [3] A szőlőfajta választása esetén a fajták rangsorát vizsgálhatjuk és ezen felül még a fajták évjáratai is sorszámozásra kerülnek. Próbáljuk ki a legnagyobbtól a legkisebbig rangsorolva számítást, a fajta paraméterrel!
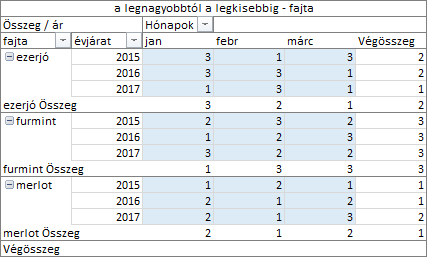
A február hónapot vizsgálva, a fajták rangsora így alakul: merlot, ezerjó, furmint. A februári árbevétel 2015-ös évjáratában az ezerjó a király, őt követi merlot és a sereghajtó a furmint.
Már csak egyetlen számítás maradt, az „Index”. A program „viszonyszám” értelemben használja ezt a többjelentésű fogalmat. Képlete: statisztikai érték * tábla érték / sor érték * oszlop érték.
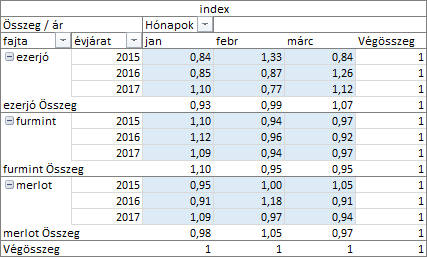
A számítás képletéből kiindulva, megállapíthatjuk, hogy az index egytől való eltérése mutatja a vizsgált statisztikai érték és a vele egy sorban és egy oszlopban álló értékek nagyságától való eltérését. Például az ezerjó 2015-ös évjáratának februári eladásaiból származó árbevétel, mind saját kategóriájában (ezerjó, 2015-ös évjárat havi eladásai), mind a többi kategória februári érbevételei közül is magasan kiemelkedik. Ezt mutatja az 1-től felfelé jelentősen eltérő 1,33 indexe (számformátummal a tizedesjegyek megjelenítését kettőre korlátoztam). Az ezerjó, 2017-es évjáratának februári árbevétele, a maga 0,77-es indexével, meglehetősen alacsony a saját kategóriájának havi, és a többi kategória februári árbevételeihez képest.
A matematikában és számítástechnikában az index sorszámot jelent. Bár ez az index egy viszonyszám, de azért ebben is van egy „kicsi” sorszám! Figyeljük csak meg! Rejtsük el a pivot táblában a részösszegeket. Készítsünk egy 9 * 3-as (sorok * oszlopok) táblázatot és celláiban számoljuk ki az indexek rangsorát a RANG.EGY függvénnyel. A képletben ne a KIMUTATÁSADATOT.VESZ függvényt, hanem cella- illetve tartomány hivatkozást használjunk!
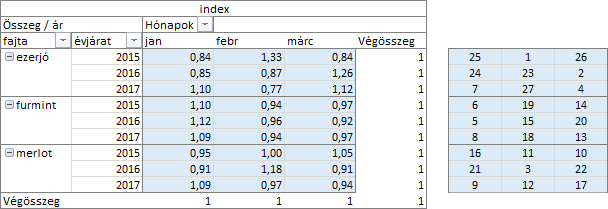
Ne felejtsük el, ez nem a statisztikai értékek rangsora, hanem az indexeké. Talán azt mondhatjuk, hogy ez a statisztikai értékek „harmonikus” rangsora. Persze ezt csak én mondom!
Összefoglalva a tapasztalatainkat: az érték mező eredményének feldolgozhatóságával a program újabb lehetőségeket biztosít adataink elemzéséhez. Szabadság, egyenlőség, testvériség!
 margitfalvi.arpad@gmail.com
margitfalvi.arpad@gmail.com
