adattípus-kezelés vágólapos tábla-készítéskor

2018-07-24 Excel 2016
A cikksorozat eddigi darabjaiban az importálásos-, ebben a részben a vágólapos tábla-készítés során alkalmazott adattípus-kezelő automatizmusokat ismertetem. Az azonos felépítésű, tehát azonos oszlopokat, azonos sorrendben tartalmazó, táblázatokat vágólappal egyesíthetjük. Az egyesítő tábla létrehozása a bővítmény ablakában, a Beillesztés-, feltöltése a Beillesztés hozzáfűzéssel paranccsal történik.
Előfordulhat, hogy már a műveletsor első lépésében elakadunk. A villámnézet jóváhagyását követően a bővítmény hibaüzenetet jelenít meg. Az alábbi képen, egy ilyen esetet látunk: a háttérben a vágólapra helyezett tábla, az előtérben a hibaüzenet áll.
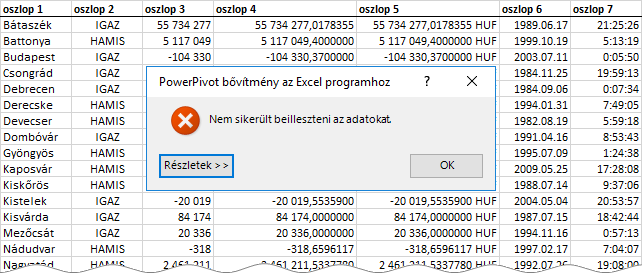
Ha egyesével próbáljuk az oszlopokat a PowerPivot ablakban „beilleszteni”, akkor kiderül, hogy a problémát a negyedik oszlop okozza. Pontosabban: a negyedik oszlopban álló tizedes vesszők. Sajnos ez a jelenség program-hiba, az Excel 2016-os, magyar nyelvű verziójában! Az angol verzió, ebből a szempontból, hibátlan. Az egyetlen, de nem minden esetben tökéletes, megoldás: a tizedes törtek átalakítása beépített, HUF pénznem-formátummá. Természetesen az összes táblázatban! Miután létrehoztuk az egyesítő táblát, a mező adattípusát visszaalakíthatjuk Tizedes tört számmá a Kezdőlap, Formátum, Adattípus paranccsal!
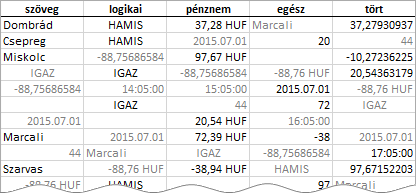
A továbbiakban az Excel 2016-os, angol nyelvű változatában mutatom be, az egyesítő tábla létrehozásával kapcsolatos adattípus műveleteket. A Paste (Beillesztés) parancsot követő első automatizmus, az egyes mezők adattípusának meghatározása. Először vizsgáljuk meg az azonos adattípusú adatokat tartalmazó, tehát homogén, forrás-oszlopok új adattípusát.
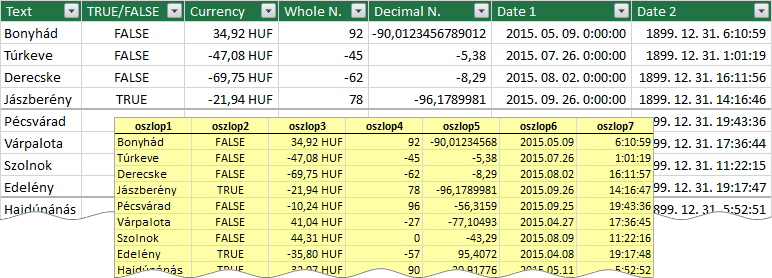
A kép hátterében a létrehozott tábla, előtte a vágólapra helyezett Excel táblázat áll. A mezőnevek az automatikusan beállított adattípust mutatják. A bővítmény szövegnek tekinti a karakter-láncokat, az aposztróffal beírt számokat és a hibaértékeket (például #DIV/0!-t, magyarul #ZÉRÓOSZTÓ!). A vágólapról beillesztett szövegként formázott számokat, százalékokat, természetes törteket, normál alakban felírt számokat, egyéni kóddal formázott számokat és pénzeket a PowerPivot egész vagy tizedes tört számnak veszi. A beépített pénznem formátumú (HUF) számokat a bővítmény négy tizedesjegyre kerekíti valamint a dátumokat a 0:00:00 időponttal, az időpontokat a 1899.12.31. dátummal egészíti ki.
A különböző típusú adatokat tartalmazó forrás-oszlopból a bővítmény Text (Szöveg) adattípusú mezőt készít, két kivétellel: [1] az egész és tizedes tört számokat, [2] számokat és beépített formátumú pénzeket tartalmazó oszlopok. Az előbbi oszlop mindig Decimal Number (Tizedes tört szám), utóbbi Currency (Pénznem) adattípusú mezőt eredményez, az egyes adattípusok előfordulásától függetlenül.
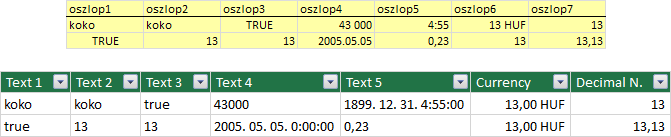
A képen felül a vágólapra helyezett táblázatot, alul az elkészült táblát látjuk. A mezőnevek az automatikusan beállított adattípust mutatják.
A nem homogén forrás-oszlopú mezők tehát Text (Szöveg) adattípusúak lesznek. Ha azonban az egyik adattípus bejegyzéseinek száma eléri a rekordok számának 95 százalékát, felfelé, egész százalékra kerekítve, akkor a bővítmény felajánlja egy számított mező automatikus létrehozását, amelynek adattípusa a többségben lévő adattípus lesz.

A képen a homogenizáló mező felajánlásának egyetlen feltétellét látjuk, két különböző megfogalmazásban. A lehetőségre a mezőnév mellett álló, pici jelzés figyelmeztet. A vegyes adattípusú, döntően szöveg vagy pénznem adattípusú bejegyzéseket tartalmazó mezők esetén automatikus homogenizálás nem lehetséges.
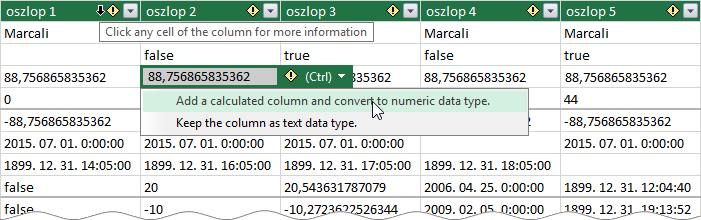
Ha rámutatunk a mezőnév mellett álló, felkiáltójeles ábrára, akkor a bővítmény a Click any cell of the column for more information (További információért kattintson az oszlop bármelyik cellájára) feliratot jeleníti meg, majd követve az utasítást, az Add a calculated column and convert to <az oszlopban többségben lévő adattípus> data type (Számított oszlop hozzáadása és < … > adattípusra konvertálása) paranccsal kérhetjük a mező létrehozását.
Az alábbi táblázatban tekintsük át, mi történik a többségben lévő típustól eltérő adatokkal a homogenizáló mezőben. Az oszlopok tartalmazzák a többségben lévő-, a sorok az attól eltérő adattípusokat.
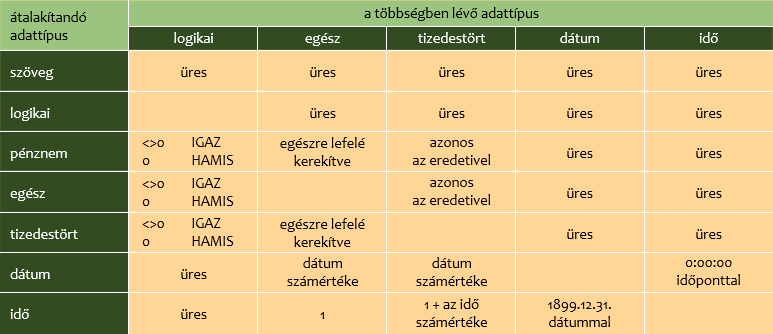
A vegyes adattípusú, döntően idő bejegyzéseket (ó:pp:mm) tartalmazó mező automatikus homogenizáló képlete hibás! A képletet a mező tetszőleges bejegyzésére kattintva, a szerkesztőlécen javíthatjuk: =IF( NOT( ISERROR( TIMEVALUE( [mezőnév] ))) ; TIMEVALUE( [mezőnév] )). A többségében dátum-idő (éééé. hh. nn. ó:pp:mm) bejegyzéseket tartalmazó mező homogenizáló képlete, amely minden dátum-tartalomra általánosan is használható, ez legyen: =IF( NOT( ISERROR( DATEVALUE( [mezőnév] ))) ; DATEVALUE( [mezőnév] ) + TIMEVALUE( [mezőnév] )).
A pénznem és tizedes tört adattípusú bejegyzéseket az INT függvény, a számegyenesen balra elmozdulva, egészre alakítja át. Például a tizenkettő egész három (12,3) tizenkettő (12), a mínusz tizenkettő egész három (-12,3) mínusz tizenhárom (-13) lesz.
A homogenizálás során törölt bejegyzések nem szerepelnek majd a pivot táblás elemzésben, ezért célszerű, még az egyesítő tábla elkészítése előtt, megtekinteni ezeket az adatokat. Erre a célra a legalkalmasabb a képleten alapuló feltételes formázás. A képletben az Excel típusellenőrző függvényeit használhatjuk. A szöveg-, a logikai-, a pénznem-, az egész-, és a tizedes tört adattípusok detektálása ezekkel a függvényekkel nem okoz problémát, de a dátumok és az időpontok azonosítására alkalmas CELLA (CELL) függvény, magyar felhasználói környezetben, erre a feladatra, csak erősen korlátozott mértékben alkalmas.

A képletek nem tökéletesek, mert a fent ismertetett probléma miatt, [1] az egész számok között a dátumok, [2] a tizedes törtek között az időpontok is formázatlanul jelennek meg.
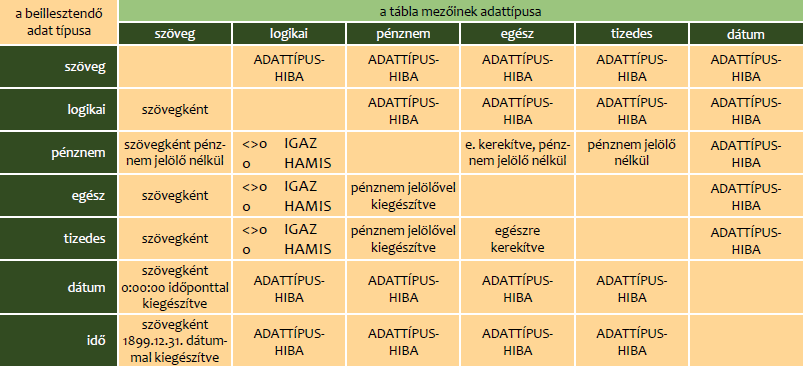
Az egyesítő tábla létrehozása után a további táblázatok sorainak beillesztésekor a bővítmény a mező adattípusára konvertálja az attól eltérő típusú adatokat. Ha ez nem lehetséges, akkor a PowerPivot a Paste Preview (Beillesztés villámnézete) panel alján a Type Mismatch… (Típuseltérés…) kezdetű, a cél-mező nevét is tartalmazó szöveget jelenít meg. Több hiba esetén, jobbról balra haladva, az első megsértett adattípusú cél-mező nevét olvashatjuk az üzenetben. Az adattípus-hiba meghiúsítja a sorok beillesztését. Ha az oszlopneveket is a vágólapra másoltuk, akkor ne felejtsük el ezt, a panel bal alsó sarkában álló jelölőnégyzettel közölni, különben a nevek is adattípus hibát okoznak. Az alábbi táblázatban számba veszem az egyes adattípusok kezelésének módját Paste Append (Beillesztés hozzáfűzéssel) utasítást követően. A táblázatban az üres cellák az eredeti adat beillesztését jelentik.
Visszatérve a magyar verzió hibájára és javítására: a tizedes törtek átformálása pénznemmé, majd az egyesítő tábla elkészülte után, visszaalakítása tizedes törtté, adatvesztéssel járhat. Ennek oka, mint láttuk, a Currancy (Pénznem) adattípusú mező forrás-adatainak négy tizedes jegyre történő kerekítése. Az angol verzióban bemutatott minden további művelet a magyar változatban is működik, de a hiba javításából eredő, esetleges plusz feladatokról nem szabad elfelejtkeznünk!
 margitfalvi.arpad@gmail.com
margitfalvi.arpad@gmail.com
